How compare-ratings.com works
RaterBayes uses the same modelling approach as the Bigger or False Discovery Rate (BFDR), implemented in the priorsplitteR R package. For full details of the statistical approach, simulation experiments, and applications of the BFDR method to human genetic data, please read this preprint.
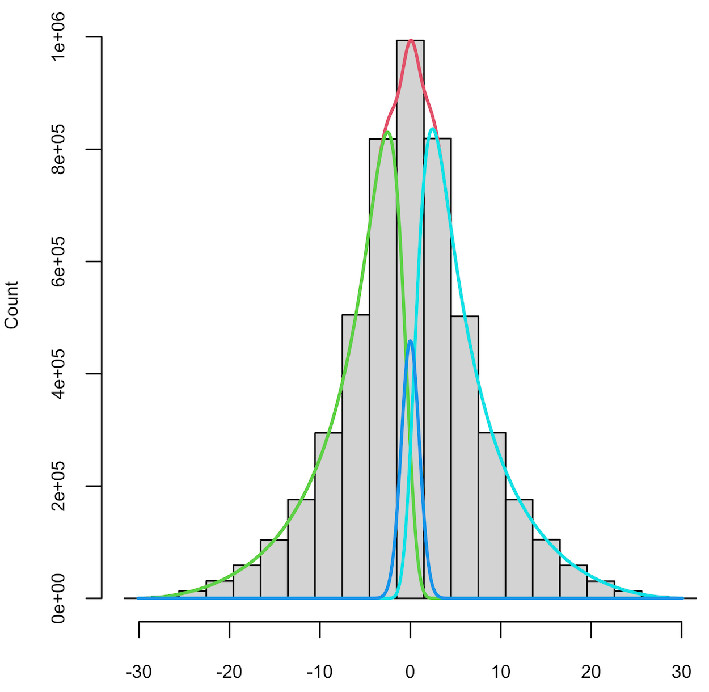
The histogram below shows the distribution of differences between ratings of Amazon products. A large database of Amazon products is used to randomly select pairs of products, then take the difference between those two ratings. The difference is scaled by its standard error, which can be computed from the distribution of ratings in each star category (1-5). Even though a difference might be positive, it is possible that this is due to statistical noise, and that the true difference is in fact negative. The curves show the distribution of ratings differences that have truly negative, truly indistinguishable from zero, and truly positive. The computation of these distributions is powered by the priorsplitteR R package. RaterBayes takes the ratings from the two products you have entered, calculates the scaled difference in ratings, and looks it up on these distributions using Bayes Theorem, to find the probability that it belongs to each, implying that product A is rated either better, the same as or worse than product B.
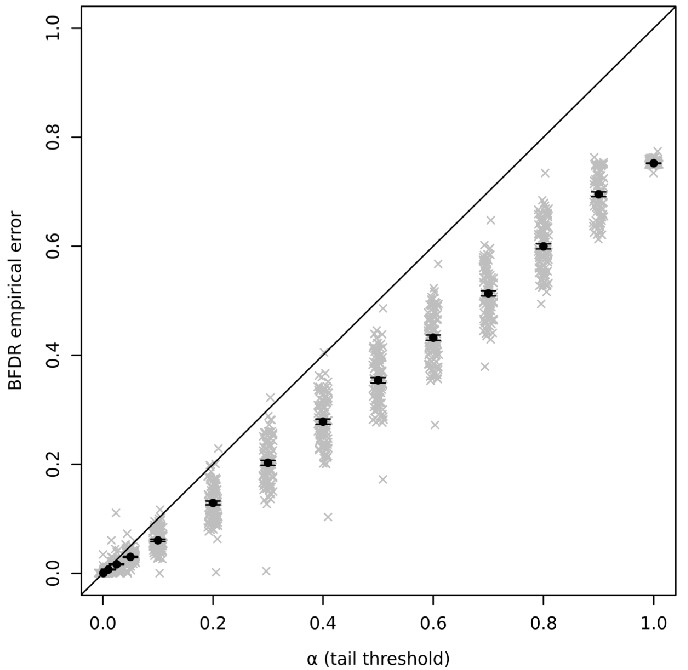
PriorsplitteR has been verified using simulated datasets in which we know which variables have higher or lower scores than others. The Figure below shows that one of its key outputs, the Bigger or False Discovery Rate, which measures how many scores in the dataset exceed a given variable, is accurately controlled.